主要Focusing on四个重要的讨论点,When, How, Why, What
SQL Basic
WHAT IS SQL?
SQL stands for Structured Query Language.
SQL lets you access and manipulate databases.
RDBMS
RDBMS stands for Relational Database Management System.
RDBMS is the basis for SQL, and for all modern database systems such as MS SQL Server, IBM DB2, Oracle, MySQL, and Microsoft Access.
The data in RDBMS is stored in database objects called tables. A table is a collection of related data entries and it consists of columns and rows.
Non-relational Databases vs. Relational Databases
SQL
- DQL / DRL (Data Query Language) :
SELECT, FROM, WHERE, ORDER, GROUP, HAVING - DDL (Data Definition Language) :
CREATE, ALTER, DROP, TRUNCATE, RENAME - DML (Data Manipulation Language) :
INSERT, UPDATE, DELETE - DCL (Data Control Language) :
GRANT, REVOKE - TCL (Transaction Control Language):
COMMIT, ROLLBACK, SAVEPOINT
SQL Common Key Words
Constraint
-
NOT NULL
NOT NULL 约束强制列不接受 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
The NOT NULL constraint enforces a column to NOT accept NULL values.
This enforces a field to always contain a value, which means that you cannot insert a new record, or update a record without adding a value to this field. -
UNIQUE
UNIQUE 约束唯一标识数据库表中的每条记录。
UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
PRIMARY KEY 拥有自动定义的 UNIQUE 约束。
请注意,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
The UNIQUE constraint ensures that all values in a column are different.
Both the UNIQUE and PRIMARY KEY constraints provide a guarantee for uniqueness for a column or set of columns.
A PRIMARY KEY constraint automatically has a UNIQUE constraint.
However, you can have many UNIQUE constraints per table, but only one PRIMARY KEY constraint per table. -
PRIMARY KEY
PRIMARY KEY 约束唯一标识数据库表中的每条记录。主键建立时自带聚集索引。
主键必须包含唯一的值。主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
The PRIMARY KEY constraint uniquely identifies each record in a table. The PRIMARY KEY will automatically have a cluster index.
Primary keys must contain UNIQUE values, and cannot contain NULL values.
A table can have only ONE primary key; and in the table, this primary key can consist of single or multiple columns (fields). -
FOREIGH KEY
一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY。
包含外键的表称为子表,包含候选键(Candidate Key)的表称为引用表或父表。
FOREIGN KEY 约束用于预防破坏表之间连接的动作。
FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
A FOREIGN KEY is a key used to link two tables together. A FOREIGN KEY is a field (or collection of fields) in one table that refers to the PRIMARY KEY in another table.
The table containing the foreign key is called the child table, and the table containing the candidate key is called the referenced or parent table.
The FOREIGN KEY constraint is used to prevent actions that would destroy links between tables.
The FOREIGN KEY constraint also prevents invalid data from being inserted into the foreign key column, because it has to be one of the values contained in the table it points to. -
CHECK
CHECK 约束用于限制列中的值的范围。
如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
如果对一个表定义 CHECK 约束,那么此约束会在特定的列中对值进行限制。
The CHECK constraint is used to limit the value range that can be placed in a column.
If you define a CHECK constraint on a single column it allows only certain values for this column.
If you define a CHECK constraint on a table it can limit the values in certain columns based on values in other columns in the row. -
DEFAULT
DEFAULT 约束用于向列中插入默认值。
如果没有规定其他的值,那么会将默认值添加到所有的新记录。
The DEFAULT constraint is used to provide a default value for a column.
The default value will be added to all new records IF no other value is specified.
VARCHAR, VACHAR2, CHAR
-
CHAR
The CHAR datatype stores fixed-length character strings. When you create a table with a CHAR column, you must specify a string length (in bytes or characters) between 1 and 2000 bytes for the CHAR column width. The default is 1 byte. Oracle then guarantees that:
- When you insert or update a row in the table, the value for the CHAR column has the fixed length.
- If you give a shorter value, then the value is blank-padded to the fixed length.
- If a value is too large, Oracle Database returns an error.
-
VARCHAR, VARCHAR2
The VARCHAR2 datatype stores variable-length character strings. When you create a table with a VARCHAR2 column, you specify a maximum string length (in bytes or characters) between 1 and 4000 bytes for the VARCHAR2 column. For each row, Oracle Database stores each value in the column as a variable-length field unless a value exceeds the column’s maximum length, in which case Oracle Database returns an error.
- Varchar can identify NULL and empty string separately. Varchar2 cannot identify both separately. Both considered as same for this.
- Varchar is ANSI Sql standard. Varchar2 is Oracle standard.
AGGREGATION FUNCTIONS (MIN / MAX / AVG / SUM / COUNT)
Aggregate functions return a single result row based on groups of rows, rather than on single rows. Aggregate functions can appear in select lists and in ORDER BY and HAVING clauses. They are commonly used with the GROUP BY clause in a SELECT statement, where Oracle Database divides the rows of a queried table or view into groups. In a query containing a GROUP BY clause, the elements of the select list can be aggregate functions, GROUP BY expressions, constants, or expressions involving one of these. Oracle applies the aggregate functions to each group of rows and returns a single result row for each group.
Many (but not all) aggregate functions that take a single argument accept these clauses:
- The syntax diagrams for aggregate functions in this chapter use the keyword
DISTINCTfor simplicity. - ALL causes an aggregate function to consider all values, including all duplicates.
For example, the DISTINCT average of 1, 1, 1, and 3 is 2. The ALL average is 1.5. If you specify neither, then the default is ALL.
DROP / TRUNCATE / DELETE
-
DROP
DROP is used to delete a whole database or just a table.The DROP statement destroys the objects like an existing database, table, index, or view.
- The DROP command removes a table from the database.
- All the tables’ rows, indexes and privileges will also be removed.
- No DML triggers will be fired.
- The operation cannot be rolled back.
- DROP and TRUNCATE are DDL commands, whereas DELETE is a DML command.
- DELETE operations can be rolled back (undone), while DROP and TRUNCATE operations cannot be rolled back.
-
TRUNCATE
TRUNCATE SQL query removes all rows from a table, without logging the individual row deletions.
- TRUNCATE is executed using a table lock and whole table is locked for remove all records.
- We cannot use WHERE clause with TRUNCATE.
- TRUNCATE removes all rows from a table.
- Minimal logging in transaction log, so it is faster performance wise.
- TRUNCATE TABLE removes the data by deallocating the data pages used to store the table data and records only the page deallocations in the transaction log.
- TRUNCATE TABLE通过取消分配用于存储表数据的数据页来删除数据,并仅在事务日志中记录页面的解除分配。
- Identify column is reset to its seed value if table contains any identity column.
- Truncate uses less transaction space than the Delete statement.
- Truncate cannot be used with indexed views.
- TRUNCATE is faster than DELETE.
-
DELETE
To execute a DELETE queue, delete permissions are required on the target table. If you need to use a WHERE clause in a DELETE, select permissions are required as well.
- DELETE is a DML command.
- DELETE is executed using a row lock, each row in the table is locked for deletion.
- We can use where clause with DELETE to filter & delete specific records.
- The DELETE command is used to remove rows from a table based on WHERE condition.
- It maintain the log, so it slower than TRUNCATE.
- The DELETE statement removes rows one at a time and records an entry in the transaction log for each deleted row.
- Identity of column keep DELETE retains the identity.
- To use Delete you need DELETE permission on the table.
- Delete uses the more transaction space than Truncate statement.
- Delete can be used with indexed views.
UNION / UNIONALL / MINUS / INTERSECT
-
UNION / UNIONALL
- UNION
The UNION command combines the result set of two or moreSELECTstatements (only distinct values).

- UNIONALL
The UNION ALL command combines the result set of two or moreSELECTstatements (allows duplicate values).
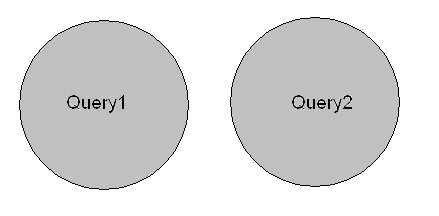
- UNION
-
MINUS / INTERSECT
- MINUS
MINUS returns the difference between the first and secondSELECTstatement. It is the one where we need to be careful which statement will be put first, cause we will get only those results that are in the firstSELECTstatement and not in the second.
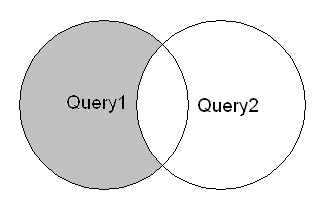
- INTERSECT
INTERSECT is opposite from MINUS as it returns us the results that are both to be found in first and secondSELECTstatement.
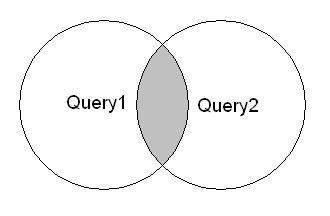
- MINUS
VIEW & TEMPORARY TABLE
-
VIEW
Views in SQL are kind of virtual tables. A view also has rows and columns as they are in a real table in the database. We can create a view by selecting fields from one or more tables present in the database. A View can either have all the rows of a table or specific rows based on certain condition.What’s the advantages?
- Improves the performance of data retriving.
- Limit the degrees of exposure of the underlying tables to the outer world.
-
Temporary Table
In Oracle Database, global temporary tables are permanent objects whose data are stored on disk and automatically deleted at the end of a session or transaction. In addition, global temporary tables are visible to all sessions currently connected to the database.
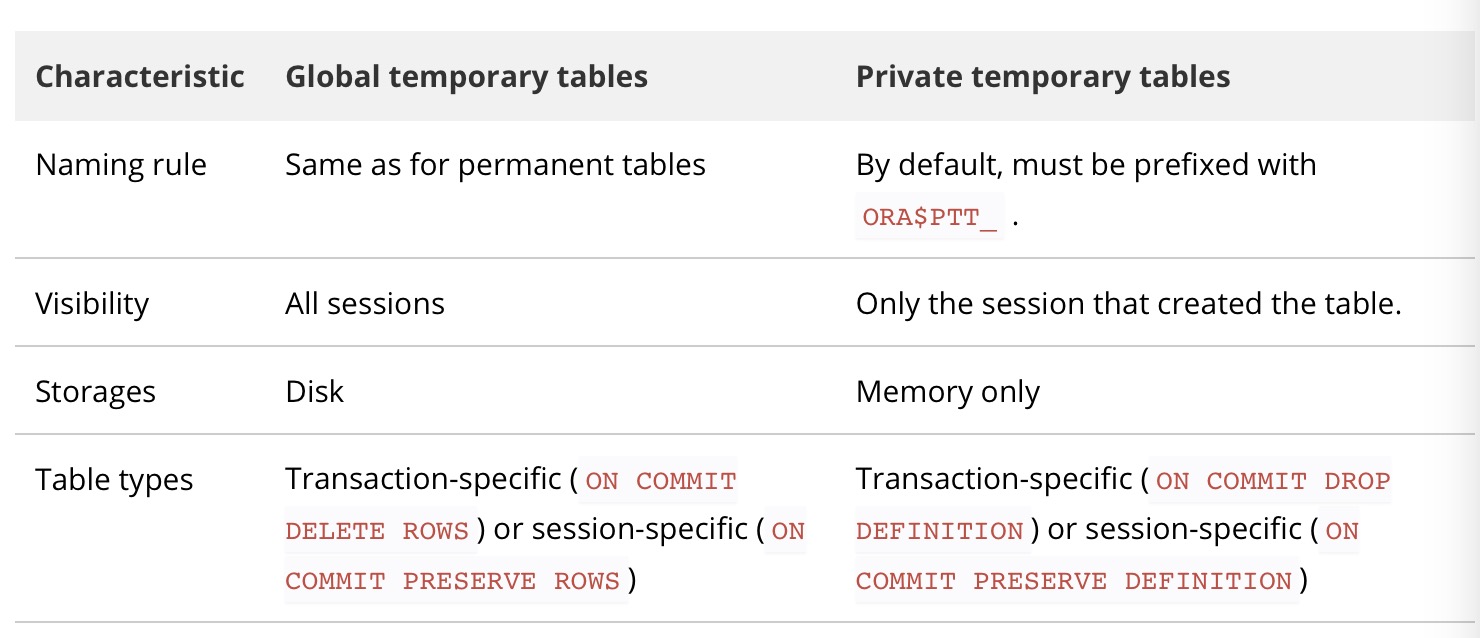
-
VIEW vs. TEMPORARY TABLE
Modifications on view could change the original table data. However, the modification on temp will keep the original table intacted. And the modification on oringal table after create the view will have effects on the view. On the other hands, temp table would not be affected.
Transaction
What’s transaction?
A transaction is a sequence of operations performed (using one or more SQL statements) on a database as a single logical unit of work.
Transaction Principles
-
Atomic
A transaction is a logical unit of work which must be either completed with all of its data modifications, or none of them is performed.
一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样。 -
Consistent
At the end of the transaction, all data must be left in a consistent state.
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。 -
Isolate
Modifications of data performed by a transaction must be independent of another transaction. Unless this happens, the outcome of a transaction may be erroneous.
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。 -
Durable
When the transaction is completed, effects of the modifications performed by the transaction must be permanent in the system.
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
Transaction Statements
COMMIT:提交更改;ROLLBACK:回滚更改;SAVEPOINT:在事务内部创建一系列可以 ROLLBACK 的还原点;SET TRANSACTION:命名事务, 用来设置事务隔离级别。
Isolation Level
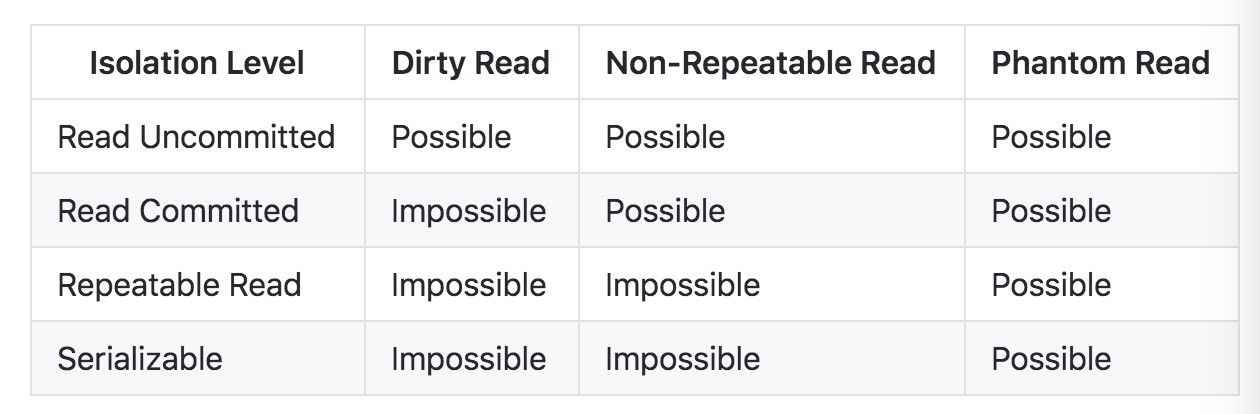
- 未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
- 提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
- 可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读
- 串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
Concurrency Anomalies
-
Dirty Read
A dirty read occurs if one transaction reads data that has been modified by another transaction.
就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。 -
Non-Repeatable Read
A non-repeatable read occurs when a object is read twice within a transaction; and between the reads, it is modified by another transaction, therefore, the second read returns different values as compared to the first.
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。 -
Phantom Read
Phantom reads are of a totally different nature than the anomalies introduced previously.
第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
PL/SQL
Stored Procedure / Function
-
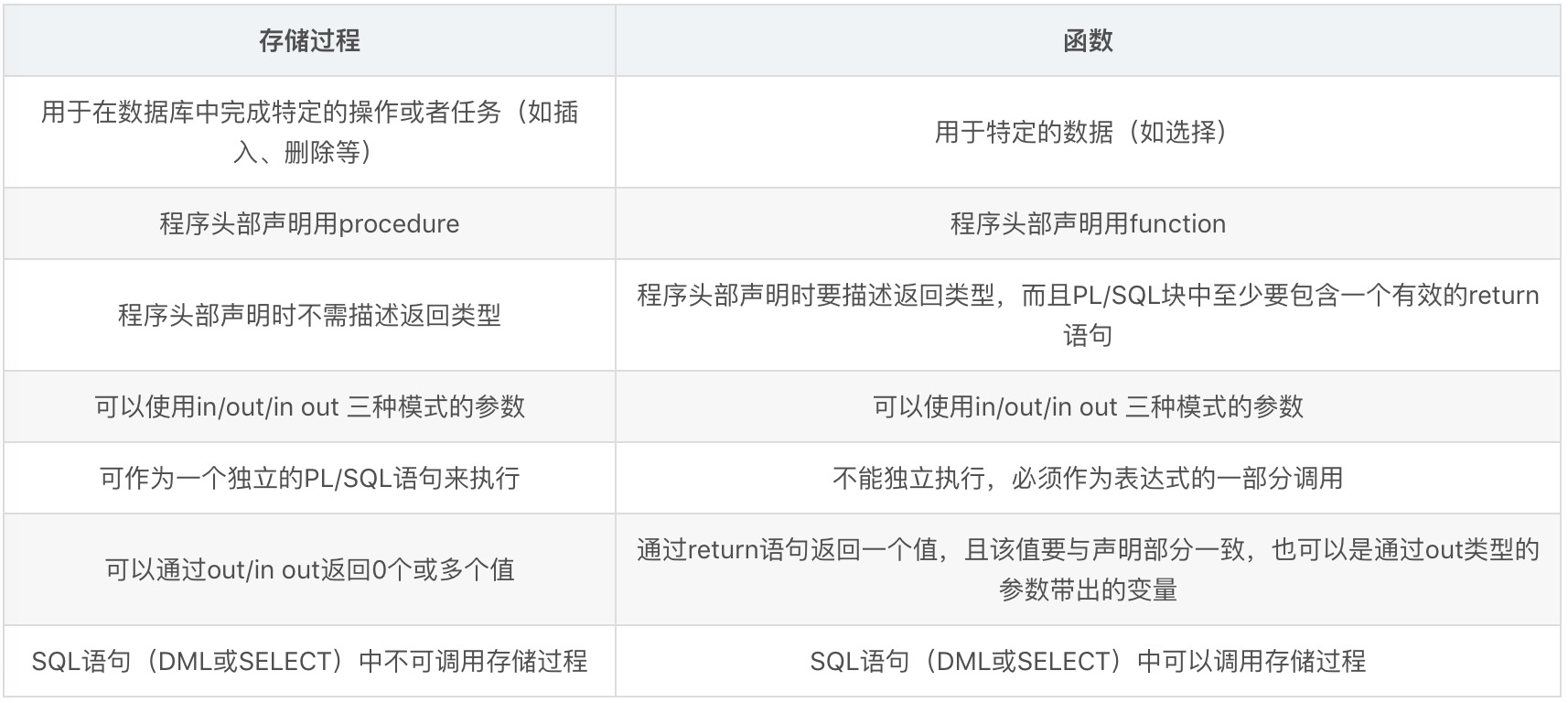
Stored Procedure vs. Function

Summary
1.一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
2.对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
3.存储过程一般是作为一个独立的部分来执行(EXEC执行),而函数可以作为查询语句的一个部分来调用(SELECT调用),由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
4.当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。 Procedure cache中保存的是执行计划 (execution plan) ,当编译好之后就执行procedure cache中的execution plan,之后SQL SERVER会根据每个execution plan的实际情况来考虑是否要在cache中保存这个plan,评判的标准一个是这个execution plan可能被使用的频率;其次是生成这个plan的代价,也就是编译的耗时。保存在cache中的plan在下次执行时就不用再编译了。 -
Stored Procedure
存储过程(Stored Procedure)
是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。
存储过程是由流控制和SQL 语句书写的过程,这个过程经编译和优化后存储在数据库服务器中,应用程序使用时只要调用即可。
在Oracle 中,若干个有联系的过程可以组合在一起构成程序包。Advantage:
- 存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
- 当对数据库进行复杂操作时(如对多个表进行Update、Insert、Query、Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
- 存储过程可以重复使用,可减少数据库开发人员的工作量。减少网络交互的成本。
- 安全性高,可设定只有某用户才具有对指定存储过程的使用权。
Disadvantage
- 不可移植性,每种数据库的内部编程语法都不太相同,当你的系统需要兼容多种数据库时,最好不要用存储过程。
- 学习成本高,DBA一般都擅长写存储过程,但并不是每个程序员都能写好存储过程,除非你的团队有较多的开发人员熟悉写存储过程,否则后期系统维护会产生问题。
- 业务逻辑多处存在,采用存储过程后也就意味着你的系统有一些业务逻辑不是在应用程序里处理,这种架构会增加一些系统维护和调试成本。
- 存储过程和常用应用程序语言不一样,它支持的函数及语法有可能不能满足需求,有些逻辑就只能通过应用程序处理。
- 如果存储过程中有复杂运算的话,会增加一些数据库服务端的处理成本,对于集中式数据库可能会导致系统可扩展性问题。
- 为了提高性能,数据库会把存储过程代码编译成中间运行代码(类似于Java的class文件),所以更像静态语言。当存储过程引用的对像(表、视图等等)结构改变后,存储过程需要重新编译才能生效,在24*7高并发应用场景,一般都是在线变更结构的,所以在变更的瞬间要同时编译存储过程,这可能会导致数据库瞬间压力上升引起故障。
-
Function
只能返回一个变量的限制。而存储过程可以返回多个。而函数是可以嵌入在sql中使用的,可以在select中调用,而存储过程不行。执行的本质都一样。
函数限制比较多,比如不能用临时表,只能用表变量还有一些函数都不可用等等。而存储过程的限制相对就比较少。
Trigger
-
What is a Trigger?
触发器是一种特殊的存储过程,触发器一般由事件触发并且不能接受参数,存储器由语句块去调用
A trigger is a named PL/SQL block stored in the Oracle Database and executed automatically when a triggering event takes place. The event can be any of the following:- A data manipulation language (DML) statement executed against a table e.g.,
INSERT,UPDATE, orDELETE. For example, if you define a trigger that fires before anINSERTstatement on thecustomerstable, the trigger will fire once before a new row is inserted into thecustomerstable. - A data definition language (DDL) statement executes e.g.,
CREATEorALTERstatement. These triggers are often used for auditing purposes to record changes of the schema. - A system event such as startup or shutdown of the Oracle Database.
- A user event such as login or logout.
The act of executing a trigger is also known as firing a trigger. We say that the trigger is fired.
- A data manipulation language (DML) statement executed against a table e.g.,
Cursor
-
What is a Cursor?
在PL/SQL块中执行
SELECT、INSERT、DELETE和UPDATE语句时,ORACLE会在内存中为其分配上下文区(Context Area),即缓冲区。游标是指向该区的一个指针,或是命名一个工作区(Work Area),或是一种结构化数据类型。它为应用等量齐观提供了一种对具有多行数据查询结果集中的每一行数据分别进行单独处理的方法,是设计嵌入式SQL语句的应用程序的常用编程方式。
A cursor is a pointer that points to a result of a query. PL/SQL has two types of cursors: implicit cursors and explicit cursors.

-
Implicit cursors
Whenever Oracle executes an SQL statement such as
SELECT INTO,INSERT,UPDATE, andDELETE, it automatically creates an implicit cursor. -
Explicit cursors
An explicit cursor is an
SELECTstatement declared explicitly in the declaration section of the current block or a package specification. For an explicit cursor, you have the control over its execution cycle fromOPEN,FETCH, andCLOSE.
-
Index
What is index?
Indexes are special lookup tables that the database search engine can use to speed up data retrieval.
An index helps to speed up SELECT queries and WHERE clauses, but it slows down data input, with the UPDATE and the INSERT statements. Indexes can be created or dropped with no effect on the data.
The basic syntax of a CREATE INDEX is as follows.
CREATE INDEX index_name ON table_name;
Cluster Index
Cluster index is a type of index which sorts the data rows in the table on their key values. In the Database, there is only one clustered index per table.
A clustered index defines the order in which data is stored in the table which can be sorted in only one way. So, there can be an only a single clustered index for every table. In an RDBMS, usually, the primary key allows you to create a clustered index based on that specific column.
- Characteristic of Clustered Index
- Default and sorted data storage
- Use just one or more than one columns for an index
- Helps you to store Data and index together
- Fragmentation
- Operations
- Clustered index scan and index seek
- Key Lookup
- Advantages of Clustered Index
- Clustered indexes are an ideal option for range or group by with max, min, count type queries.
- In this type of index, a search can go straight to a specific point in data so that you can keep reading sequentially from there.
- Clustered index method uses location mechanism to locate index entry at the start of a range.
- It is an effective method for range searches when a range of search key values is requested.
- Helps you to minimize page transfers and maximize the cache hits.
- Disadvantages of Clustered Index
- Lots of inserts in non-sequential order.
- A clustered index creates lots of constant page splits, which includes data page as well as index pages.
- Extra work for SQL for inserts, updates, and deletes.
- A clustered index takes longer time to update records when the fields in the clustered index are changed.
- The leaf nodes mostly contain data pages in the clustered index.
Non-Cluster Index
A Non-clustered index stores the data at one location and indices at another location. The index contains pointers to the location of that data. A single table can have many non-clustered indexes as an index in the non-clustered index is stored in different places.
For example, a book can have more than one index, one at the beginning which displays the contents of a book unit wise while the second index shows the index of terms in alphabetical order.
A non-clustering index is defined in the non-ordering field of the table. This type of indexing method helps you to improve the performance of queries that use keys which are not assigned as a primary key. A non-clustered index allows you to add a unique key for a table.
-
Characteristics of Non-clustered Indexes
- Store key values only
- Pointers to Heap/Clustered Index rows
- Allows Secondary data access
- Bridge to the data
- Operations of Index Scan and Index Seek
- You can create a nonclustered index for a table or view
- Every index row in the nonclustered index stores the nonclustered key value and a row locator
-
Advantages of Non-clustered index
- A non-clustering index helps you to retrieves data quickly from the database table.
- Helps you to avoid the overhead cost associated with the clustered index.
- A table may have multiple non-clustered indexes in RDBMS. So, it can be used to create more than one index.
-
Disadvantages of Non-clustered index
- A non-clustered index helps you to stores data in a logical order but does not allow to sort data rows physically.
- Lookup process on non-clustered index becomes costly.
- Every time the clustering key is updated, a corresponding update is required on the non-clustered index as it stores the clustering key.
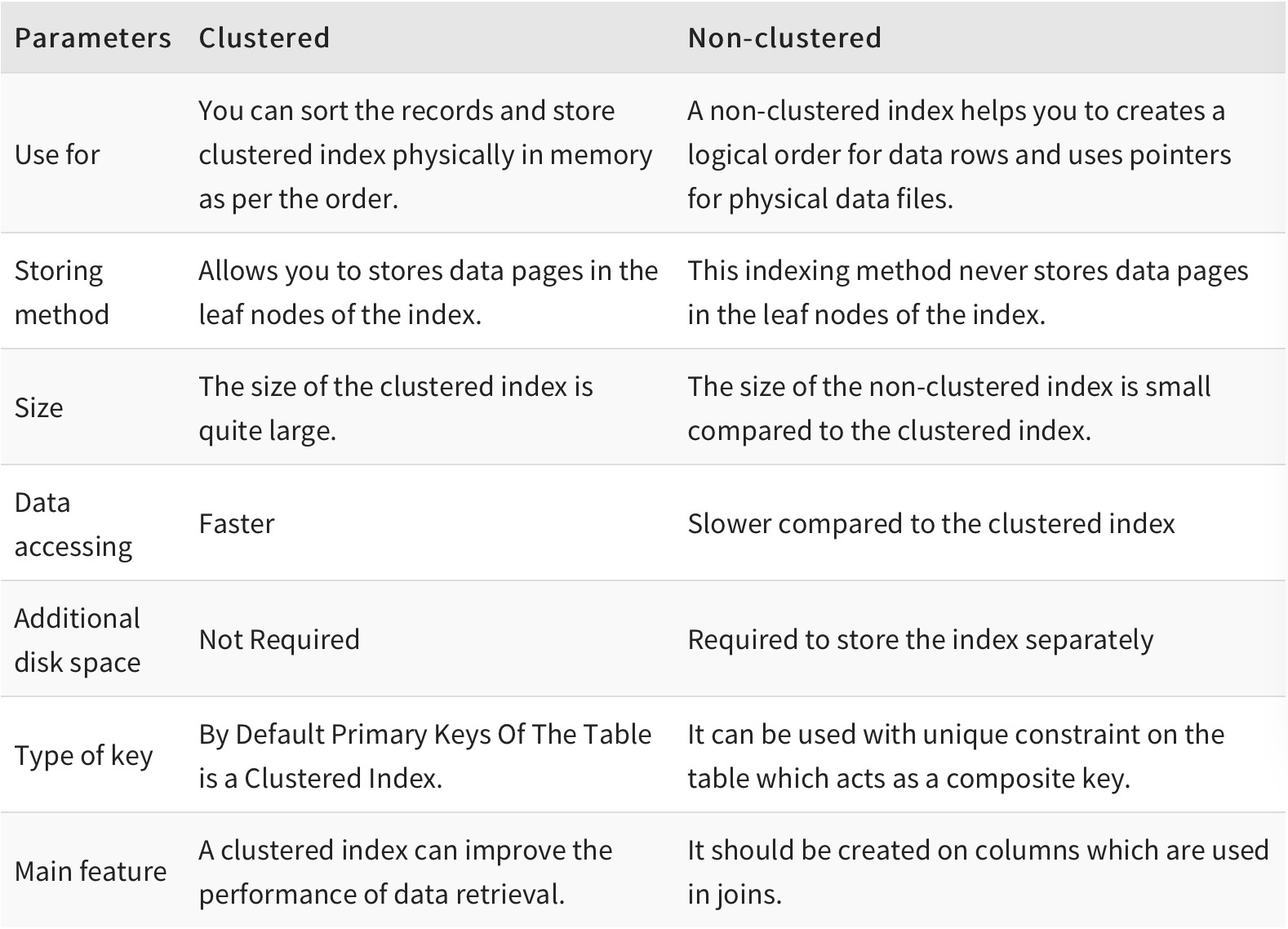
Cluster vs. Non-Cluster Index
聚集索引:可以帮助把很大的范围,迅速减小范围。但是查找该记录,就要从这个小范围中Scan了。
非聚集索引:把一个很大的范围,转换成一个小的地图。你需要在这个小地图中找你要寻找的信息的位置。然后通过这个位置,再去找你所需要的记录。
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
聚集索引表记录的排列顺序与索引的排列顺序一致。
优点是查询速度快,因为一旦具有第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。
缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排, 降低了执行速度。
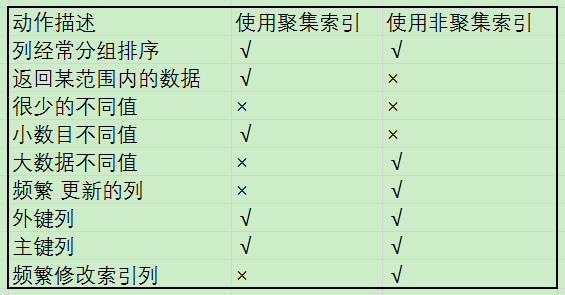
建议使用聚集索引的场合为:
- 此列包含有限数目的不同值;
- 查询的结果返回一个区间的值;
- 查询的结果返回某值相同的大量结果集。
非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致,聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。
非聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。
建议使用非聚集索引的场合为:
- 此列包含了大量数目不同的值;
- 查询的结束返回的是少量的结果集;
- order by 子句中使用了该列。